
Close
 Current atmospheric modeling is technically capable of generating historical wind data time series over a region for several heights. This 4-dimensional gridded time-series dataset is what we internally name BLOCKS at Vortex and will allow wind engineers to study the wind flow in great detail and use it as input for complex calibration, wakes, and production studies.
Current atmospheric modeling is technically capable of generating historical wind data time series over a region for several heights. This 4-dimensional gridded time-series dataset is what we internally name BLOCKS at Vortex and will allow wind engineers to study the wind flow in great detail and use it as input for complex calibration, wakes, and production studies.Besides the computational challenges of performing such a simulation for high resolutions and long periods of time, another limitation is the storage and handling of the dataset itself. BLOCKS are so voluminous and complex that traditional wind software formats are inadequate to deal with them (yet) and this hinders their widespread. Fortunately, there exist interesting candidates to become the next industry standard and in this presentation, we will show why Vortex has chosen one of them: the Zarr files.
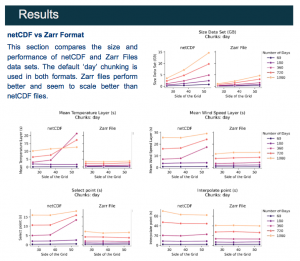
Zarr is a cloud-friendly data format implemented in Python that stores chunked, compressed N-dimensional arrays. Zarr is a young project but is already very popular, especially in parallel computing and cloud storage contexts. A key feature of a Zarr file is that the data arrays are divided into chunks (pieces) and each chunk is compressed. The optimal chunk shape depends on how one will access the data and the performance can vary greatly if chunks are chosen differently. Therefore, choosing the correct chunking for the data is the essential decision to create the “best” Zarr possible.
This study aims to show examples of 4D simulations stored in different formats to give a perspective of expected storage space and data retrieval times. The experiments have been carried out considering an input dataset of daily netCDF files corresponding to WRF (Weather Research and Forecasting) simulations and testing which is the optimal way to store the final BLOCKS dataset taking into account the:
Zarr files, even without using parallel computation or cloud storage, have improved every part of the process. The results also give important insight into how to choose chunks depending on the spatial and temporal dimensions of the dataset.
Summing up, the wind industry is undoubtedly moving towards wind resource assessment strategies that involve more and more data. Many of the popular industry formats are not able to adequately capture 4D datasets, and there is a need to explore formats that both optimize storage space and data usability, especially, formats that are optimized for cloud storage and big data processing. We would like to encourage the use of Zarr files by providing basic guidelines for chunking since we envision the Zarr format as the new standard for dealing with BLOCKS 4D datasets in the wind industry.